

ورود ابزارهای دیجیتال به فضای تحلیل و تصمیم، باعث شد کوچکترین اتفاقات و تراکنشها به عنوان داده ثبت شوند. با انباشت این دادهها، همه به این فکر افتادهاند که از آن برای تحلیل و تصمیم خودشان استفاده کنند. شرکت تترا هم تجربهای طولانی در استقرار سامانههای رصدی، تحلیل و رساندن دادهها به تصمیم داشته است. (استقرار سامانه رصد آسیبهای اجتماعی در وزارت کشور، نگاشت نقشهٔ زیستبوم هنر انقلاب در حوزه هنری، رصد کسبوکارهای اجتماعی در شهرداری) با مقایسهٔ تجربهٔ بلندمدت تترا در انجام پروژهها با شیوهٔ تعامل با داده در دیگر شرکتها و سازمانها، به نظر میرسد که یک خطای اساسی در سطح وسیعی در تعامل با دادههای اجتماعی و انسانی در حال رخ دادن است. خطایی که ریشهاش، فکر کردن بعد از جمعآوری داده است و نه قبل از آن.
گزارهٔ ۱: داده حرف میزند؛ اما اغلب هذیان میگوید
تصور عامه این است که بعد از جمعآوری داده، با کشیدن نمودارهای مختلف و محاسبهٔ شاخصهای متعدد، داده بالاخره به زبان میآید و با ما صحبت میکند. بیراه هم نمیگویند. به حرف آوردن داده ساده است. البته که زیبایی و زیادی داده هم در این خیال مؤثر است. با انواع نمودارهای دوبعدی و سهبعدی، هزاران سطرِ داده در یک تصویر خلاصه میشوند. مشکل اینجاست که در مسائل پیچیده، این تصویرِ خلاصه اغلب مطلوب هیچکسی نیست. ممکن است اول همه را به ذوق بیاورد، اما خیلی سریع بیفایدگی خودش را نشان میدهد. امید داشتن به تصاویر تصادفی داده، مثل این میماند که با مشت کوبیدن روی کیبرد بخواهید کتاب بنویسید. غیرممکن نیست، ولی به دردسرش نمیارزد.
نمودارهای جذاب Tableau، اکسل و… در ابتدا همه را متحیر میکنند. اما بعد از مدتی با یک «خب که چی؟» ساده از هم میپاشند. این دسته از نمودارها به شدت میرا و ضعیفند چون به تصمیمی منجر نمیشوند، تصویری از آینده ندارند، تنها وضعیت پیشین را توصیف میکنند و اغلب دلیلی برای توجیه وضعیت گذشته ندارند. چرا؟ چون این دادهها و نمودارهایشان به ما «مدل» تحویل نمیدهند. مثال واضح این دسته از زیباییهای توخالی، ابر کلماتی است که از شعر شعرا میکشند. ابر کلمه یک عملیات آماری روی متن است که کلمات پرتکرارتر را بزرگتر به تصویر میکشد و حسی کلی از متن میدهد. آیا با ابر کلمات میشود به باطن شعر حافظ رسید؟ آیا میشود با مرور کلماتش مثل حافظ شعر گفت؟ اگر کسی توانست با کار آماری و تحلیل داده زیبایی شعر حافظ را نشان دهد، تحلیل دادهٔ صرف هم به ابزار کلیدی تصمیمگیری تبدیل خواهد شد.

متن سمت راست توصیف دکتر شفیعی کدکنی از اشعار حافظ است و متن سمت چپ ابر کلمات @zeoses از اشعار حافظ. تعداد کلمات دو عکس تقریباً نزدیک به هم است. اما آیا میزان اطلاعاتی که از دو تصویر دریافت میکنیم هم یکسان است؟
گزارهٔ ۲: داده و روند در ارتباط با مدل معنی پیدا میکند
مدل، شبکهای از اجزا و ارتباطات میان آنهاست. مدل حالت سادهتری از واقعیت است که علاوه بر توجیه اتفاقات گذشته، پیشبینیهایی هم دربارهٔ آینده انجام میدهد. مثلاً مدل اتمی سه جزء پروتون، نوترون و الکترون را برای اتم نام میبرد و نیروهای جاذبه و دافعهٔ میان آنها را نشان میدهد. چون هم واکنشهای شیمیایی پیشین را توجیه میکند و هم پیشبینیهای درستی دربارهٔ اثرات ترکیب چند اتم یا شکافت یک اتم ارائه میکند، به اصطلاح میگوییم که «مدل کار میکند».
از آنجایی که مدل در ذهن ما شکل میگیرد، در حالت عادی هیچ مدلی وجود ندارد. این ما هستیم که با تجربهٔ واقعیت و تغییر متغیرها، انتزاع میکنیم و مدل میسازیم. در این چارچوب، تحلیل داده تلاشی برای مدلسازی با انجام عملیاتهای آماری روی متغیرهاست. اما به دلایلی که بالاتر گفتیم، این مدلها اغلب بیفایدهاند و گزارههای خروجی آن بیشتر در حد تحلیل روندها هستند تا توصیف مدلها. اگر هم مدلی وجود نداشته باشد، حرکت رو به جلو یا صورت نمیگیرد یا کورکورانه و بیجهت خواهد بود. نقش داده تدقیق، تصحیح یا توسعهٔ شناخت اولیهٔ ماست؛ نه ایجاد شناخت از صفر.
گزارهٔ ۳: منبع مدلها، فرضیات و نظریات افراد میداندار است
مدلسازی حاصل تجربه و زیستن در فضاست. نمیشود از تحلیلگر داده -که ارتباط مستقیمی با کف میدان نداشته و ارتباط غیرمستقیمش هم به متغیرهای کمی محدود شده است- انتظار مدلسازی داشت. او مشاهدهای نکرده که حال بخواهد بر پایهٔ آن مدلی بسازد. اگر هم مدلی بسازد، کورکورانه خواهد بود. مثلاً چند سال پیش درصد بالای ازدواجهای منجر به طلاق در شمال شهر تهران داغ شده بود. (روزنامه خراسان، همشهری آنلاین، تسنیم) منبع این گزارشها، آمار دفاتر ثبت ازدواج و طلاق تهران بودند. اما بعدتر با بررسیهای بیشتر مشخص شد که به دلیل سختگیری دفترخانههای جنوب شهر در ثبت طلاق و طولانی کردن فرآیند طلاق، بسیاری از زوجهای ساکن جنوب به دفاتر شمال شهر برای ثبت طلاق خودشان مراجعه میکردند و همین باعث شده تا آمار شمال تهران تا این حد بالا برود. با لحاظ کردن محل سکونت زوجها به جای محل ثبت طلاق، مشخص شد که تفاوت چندانی میان شمال و جنوب تهران در طلاق وجود ندارد.
ناچار باید به آنهایی که خاک صحنه را خوردهاند اعتماد کرد. حرف این متخصصان در قالب نظریات و فرضیات قابل استخراج است. زمینههایی که افراد آن فرصت بیشتری برای فکر کردن داشتهاند، اغلب به نظریههایی دربارهٔ چگونگی کارکرد سیستم رسیدهاند. اما در زمینههایی که در آن فرصت چندانی برای اندیشیدن وجود نداشته، نیاز است که تحلیلگر به گفتگو با افراد آن بنشیند و تلاش کند از خودآگاه یا ناخودآگاه آنها، فرضیات حاکم را استخراج کند.
فرضیه و نظریه در عمل
در انجام پروژهٔ رصد آسیبهای اجتماعی برای وزارت کشور، از مدل SimDrug الهام گرفته شد. SimDrug مدلی Agent-Based برای کاوش پیچیدگی مصرف هروئین در ملبورن استرالیا به منظور بهبود بود. این مدل بر پایهٔ دادههای واقعی مصرف هروئین در شهر ملبورن در سالهای ۱۹۹۸ تا ۲۰۰۲ ساخته شده است و شامل دستههای مختلف افراد مثل فروشندههای غیرمصرفکننده، فروشندههای مصرفکننده، معتادها، مصرفکنندههای تفننی، خدماتدهندههای درمان، افراد عادی و پلیسهاست. چنین مدلی که اجزای سیستم اعتیاد و ارتباطات میان آنها را با دقت به تصویر میکشد، تحلیلگر داده را هدایت میکند که چه دادههایی را با چه جزئیات و چه فرکانسی جمعآوری کند تا بتواند با استفاده از مدل و تغییر پارامترهای آن، چند استراتژی اصلی برای پیشروی روی میز تصمیمگیر بگذارد.
اما همهٔ حوزهها دارای نظریه و مدلهای کاربردی نیستند. در این شرایط به فرضیههای ذهنی افراد تکیه میکنیم و تا مرز نظریه آن را پیش میبریم. در جریان همکاری تترا با حوزه هنری حول تدوین نقشهٔ زیستبوم هنر انقلاب، مدام این ادعا تکرار میشد که «فضای ادبیات پایداری به دست نویسندگان زن افتاده است». فرض عموم بر این است که نه تنها تعداد نویسندگان زن در این فضا بیشتر شده، بلکه تیراژ آثار آنها هم سهم قابل توجهی پیدا کرده یا حتی بر تیراژ آثار نویسندگان مرد غلبه پیدا کرده و در کل ادبیات جنگ حالا دارد با زبانی زنانه روایت میشود. اما در بررسی دادهٔ کتب ادبیات پایداری، مشخص شد که هیچکدام از این ادعاها سنخیتی با واقعیت ندارد. سهم زنان در طول زمان از آثار کمابیش ثابت مانده و تنها عناوین پرفروش آنها با شیب بسیار آهستهای در حال افزایش است.
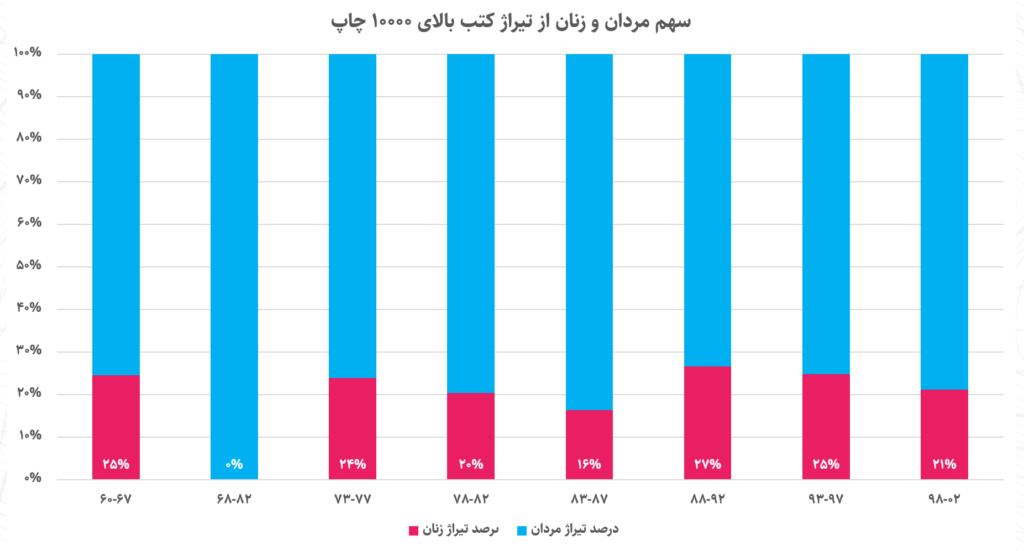
اعداد محور افقی، دورههای زمانی مختلف را از سال ۱۳۶۰ تا ۱۴۰۲ نشان میدهد.
نکتهٔ مهم در به کار بستن داده، وجود یک مدل محوری است. مدل محوری خوب، دادههای مورد نیاز را مشخص میکند، شیوهٔ تحلیل آنها را نشان میدهد و در نهایت تصویری از آینده و استراتژیهای رسیدن به هدف را نشان میدهد. در غیاب مدل محوری، ناچار به مدل ذهنی و فرضیات شهودی افراد حاضر اکتفا میکنیم. منتها مدل ذهنی افراد در مقایسه با نظریه، خدشهپذیرتر است. پس بهتر است دادهها را برای سنجش آن به خط کنیم و مسیری را تا رسیدن به نظریه طی کنیم. در همهٔ این حالات، هیچموقع از داده تمنای مدل نمیکنیم؛ چرا که داده قرار نیست شناخت بسازد؛ بلکه کارکردش کمک کردن به شناخت ماست.






دیدگاهتان را بنویسید